SD 3.5 Medium: Skip Layer Guidance! (and Fix Composition, Hands, and Anatomy)

Today, the model Stable Diffusion 3.5 Medium was released. It is a smaller model that will be appreciated by users of GPUs with smaller VRAMs (12 GB, maybe even less for some use cases; I would say it will fit into 8-10 GB on Linux).
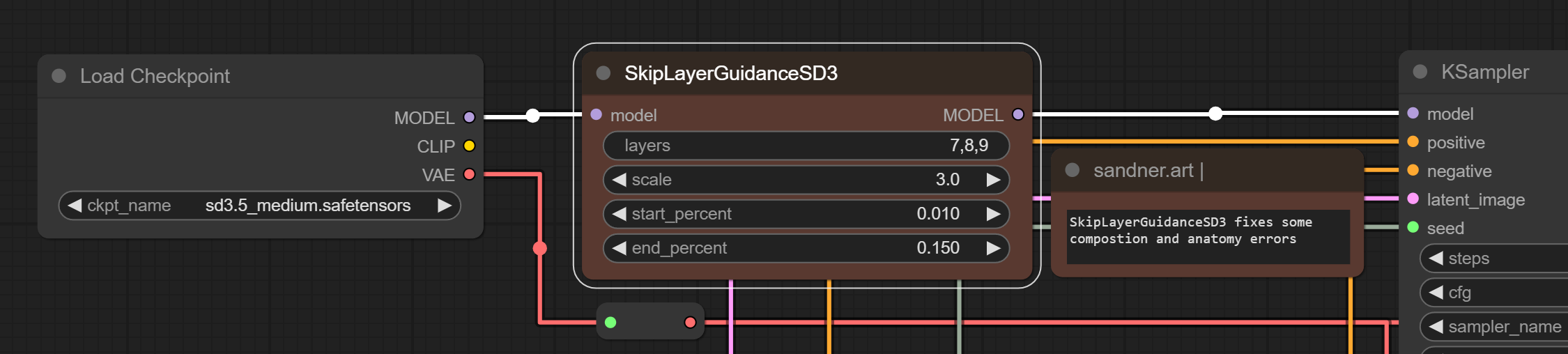
But that is not all. There is also a new node created for the Medium model that tries to fix persistent issues with anatomy and composition (the main drawback of SD 3.5, as I described in this article about the SD 3.5 Large and Turbo models), especially annoying when generating hand poses. This issue is now partially fixed (and without additional models or training).
'All good things come to those who wait.'
About the Medium 3.5 Model:
"Stable Diffusion 3.5 Medium" developed by Stability AI is a text-to-image model (Multimodal Diffusion Transformer with improvements, MMDiT-X) that uses three pretrained text encoders for prompts and self-attention modules, enhancing multi-resolution generation and image coherence. It has a different data distribution than the SD 3.5 Large model, 2.5 billion parameters (the Large model has 8 billion). SAI recommends using resolutions divisible by 64, but various resolutions are possible. They also mention a limit of 255 tokens for the T5 encoder, after which some artifacts can occur, which I have not yet encountered (or noticed).
The model itself is relatively tiny, at 5.11 GB to download. Place it in the standard Stable Diffusion model directory. It will require the usual CLIP encoders (clip_g, clip_l, t5xxl):
Download .safetensors or .gguf
- Download (and SAI workflows): https://huggingface.co/stabilityai/stable-diffusion-3.5-medium/tree/main
- GGUF (smaller, quantized) versions https://huggingface.co/city96/stable-diffusion-3.5-medium-gguf/tree/main
- Encoders: https://huggingface.co/Comfy-Org/stable-diffusion-3.5-fp8/tree/main/text_encoders
- Workflows with adjustments for SD 3.5 speed and VRAM usage (need Turbo LoRA).
You need to update Comfy UI and restart.
How to Fix Hands in SD 3.5
When you update Comfy UI, load the workflows and test the comparisons. Alternatively, insert the SkipLayerGuidanceSD3 node into your workflow and experiment with the settings. The final image may change depending on the prompt: if you have more general descriptions, the result can change substantially.
For the record, we need to admit that the fix does not work in all cases. Sometimes the result in SD Medium is even better without the fix. You need to tweak the settings for the best compositions.
Examples:



The good news is that the fix works in the Turbo and in the Large model as well.
Look, It Has Layers!
You may play with the SkipLayerGuidanceSD3 node by skipping layers for various effects and output variations. I was testing layer combinations and would say that you often achieve better results with variations of the "layers" numbers and default settings. I was trying to fix the same composition issues lately by interfering with the diffusion process using Negative Shift (workflows on my GitHub), noise, and prompt injections, with diverse results. The layer skipping is more streamlined, and as it is a temporary solution, it brings a new playground.



Possible Errors
Everything should go smoothly. However, if you encounter issues:
The SkipLayerGuidanceSD3 node is not showing, where to find it?
The node may be shown as a red rectangle in the workflow, and it may not be possible to find the node using Search or Manager. Update ComfyUI as described bellow to resolve this.
Error(s) in loading state_dict for OpenAISignatureMMDITWrapper: size mismatch for joint_blocks.0.x_block.adaLN_modulation.1.weight (CheckpointLoaderSimple):
Update, close the browser and all ComfyUI instances, and then restart. If the problem persists, you may need to reinstall the dependencies for ComfyUI. Use update_comfyui_and_python_dependencies.bat .
SD 3.5 (Medium): How It Stands to Large Model
Surprisingly good, considering the different use cases for both models. You may not get the best pictures from the start; there is some tweaking needed. The model is also quite fast, depending on your configuration.

In this example, you can see the difference in overall output between the Large and Medium models. The SLG (SkipLayerGuidanceSD3) tends to oversaturate images with some loss of detail, so the CFG and ModelSampling need to be tuned down. The examples were generated with fixed seed 50-55 using simple Euler/sgm_uniform with 25 steps (I get better results with around 50 steps for more detail). Additionally, the dpmpp_2m sampler gives nice results for general use in the Medium model.
Note that in this case, I have used the strong token "pirate," yet the output is quite diverse, and you can clearly see different characters in the images.
Conclusion
Overall, SD Medium is a good model to have, especially with a weaker GPU.The Medium model is not just a dumbed-down version of the Large model—it can produce impressive results that can differ significantly, and it has many aspects going for its favor.
Tinkering with the SkipLayerGuidanceSD3 node will add another option for output variations; it can correct an image or resurface an interesting style.
Resources
- Model Page SD Medium SAI https://huggingface.co/stabilityai/stable-diffusion-3.5-medium
- MMDiT-X Architecture https://stability.ai/news/stable-diffusion-3-research-paper
- Announcement Comfy https://blog.comfy.org/sd-35-medium/
- My workflows for SD 3.5.