Temporal Consistency: SD Animations and AnimateDiff Techniques

Achieving temporal consistency in generated AI animations is difficult, and there is not a definitive production-ready solution yet. However, we can apply several strategies to create a reasonably consistent animation.
We can use a video as a blueprint for the animation and affect the generation with ControlNet. There is also an advanced Deforum extension. However, in this article, we will explore a relatively easy technique using the AnimateDiff extension for A1111. This will allow you to create an animation from scratch (txt2img) or prepare interesting effects in img2img.
How It Works
AnimateDiff uses motion modelling module with base T2I model, trained on videoclips to produce reasonably consistent motions. All finetuned (trained or merged base models) derived from the original T2I model are then able to use the framework without additional training.
You will need such motion model, another model of your choice with the same base (SD15 or SDXL), and you can also use LoRAs trained for a specific motion.

Installation
- AnimateDiff A1111 extension: Find it in Extensions/Available/Load from list, and Install
- Install Deforum extension (needed for interpolations): Find it in Extensions/Available/Load from list, and Install
- ControlNet sd-webui-controlnet extension is recommended (but optional)
- Update and restart UI
- Download motion modules https://github.com/continue-revolution/sd-webui-animatediff#model-zoo to "\stable-diffusion-webui\extensions\sd-webui-animatediff\model". I suggest to download v2 versions, f.i.
mm_sd_v15_v2.fp16.safetensors - Download motion LoRAs https://huggingface.co/guoyww/animatediff/tree/main to \stable-diffusion-webui\models\Lora (you can crate a folder there if you want)
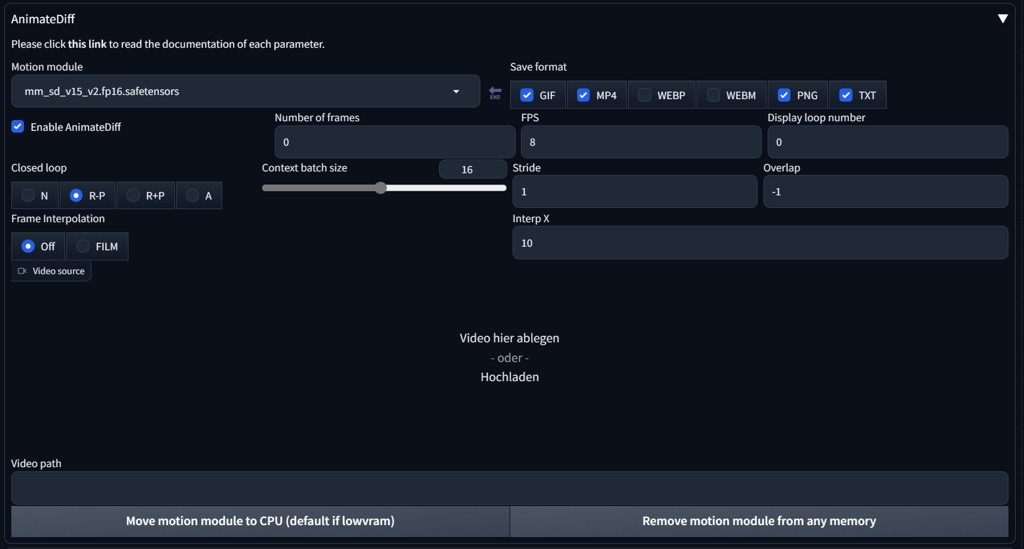
Settings: In A1111 Settings/Optimization check "Pad prompt/negative prompt to be same length" and Apply
Optional settings: If you intend to use GIF as the output, check in Settings/AnimateDiff two options "Calculate the optimal GIF palette..." and "Optimize GIFs with gifsicle...". You will need to:
- in windows cmd terminal
winget install OliverBetz.ExifTool.Development - download gifsicle from https://www.lcdf.org/gifsicle/, for windows https://eternallybored.org/misc/gifsicle/ . Put gifsicle.exe from the .zip file into your "\stable-diffusion-webui" main directory. Tip: For best results with file size, manual optimization of GIF is needed anyways.
Other Motion Models
- Interesting motion model on Civitai Improved 3D Motion Module
Working With Models
You will create a prompt and fine-tune it in the same way as with regular static AI generated image.
I recommend to start experimenting with mm_sd_v15_v2.fp16.safetensors, mm-Stabilized_mid.pth and mm-p_0.75.pth. You may achieve interesting effects with temporaldiff-v1-animatediff in img2img. Tips for the settings:
Context batch size depends on a model, for SD15 leave it for 16, SDXL can have 8. Let Number of frames on 0 to keep the context batch size, or change it to a multiple of this context batch size number.

Interpolation Interp X will create X interpolated images between frames when Frame interpolation is set to FILM. Stride and Overlap affect smoothness of movement.
LCM (Latent Consistency Models) and LoRAs in AnimateDiff
AnimateDiff allows the use of the LCM sampler (you will find it in the Sampling methods list after AD installation). It removes some artifacting, but the results are farther from the prompt than Euler a, SDE, or 2Sa with a lower CFG. Alternatively, you may use upscale/hires techniques, as shown in the examples in this article about LCM.
Prompt Travelling
You can use tokens changing with frames. Prompt travelling will activate with lines in format framenumber:prompt. The last frame must be a lower number than Context batch size.
portrait woman, curly hair
0: smiling
4: blinking
6: smirkingMotion LoRAs
Works only with v2 models (mm_sd_v15_v2.fp16.safetensors). You can add LoRAs into a prompt and use it this way:
<lora:v2_lora_ZoomOut:0.85>SDXL
SDXL models need motion models trained for SDXL, f.i. hsxl_temporal_layers.f16.safetensors (for this SDXL model set Context batch size to 8). The experiments are very time consuming, I suggest the minimum resolution of 1024x768 and the best gear available.
IMG2IMG Tips
In img2img tab, set starting image into main generation window and end image into AnimateDiff window. Adjust the prompt as needed. Changing latent power will change the effect of the first and last frame on the scene.
ControlNet, TemporalNet Models, and Using a Video as a Base for an Animation (V2V)
Simple way on how to use ControlNet with AnimateDiff:
- Set and enable AnimateDiff and insert "Video source" video
- Enable ControlNet, and just pick a control type (Canny, Softedge etc.). You do not need to change anything else (but you may adjust Control or Resize modes), AnimateDiff will pass video images into ControlNet.
We will take a look at other combined techniques for achieving a reasonable temporal consistency in the next article. In AnimateDiff, you may experiment with base video in txt2img and img2img modes (albeit all examples in this article were created just with prompt engineering using Photomatix v2 model without any additional videos). Also, the ControlNet settings and units will affect the final output in AnimateDiff.
Conclusion
Motion models are limited with training dataset, yet the result can be very good, if there is not a dramatic movement in the scene. The clips are short— it is sufficient for experiments. Motion LoRAs does not have very good datasets, but the idea is very promising.



References
- AnimateDiff for A1111 https://github.com/continue-revolution/sd-webui-animatediff
- AnimatedDiff Implementation https://github.com/guoyww/AnimateDiff/
- AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning https://arxiv.org/abs/2307.04725

