Run Large Language Models Locally: A Practical Guide to Local LLMs (Llama3, Gemma, Mistral)

Large Language Models (LLMs) have changed the way we work, generating human-quality (kind of) text, translating languages, and otherwise help developing creative content. But what if you could harness this power on your own terms, without relying on cloud limitations and potential privacy concerns? This guide empowers you to do just that! We'll walk you through the practical steps of setting up and running resource-friendly LLMs directly on your local machine. Whether you're a curious hobbyist, a developer seeking more control, or an artist exploring new creative avenues, this guide equips you to unlock the potential of LLMs locally.
While some Large Language Models (LLMs) are incredibly powerful, they often require massive amounts of VRAM to run effectively. This can be a significant barrier for those who don't have access to high-end computing resources. This guide takes a different approach, focusing on smaller, faster, and highly effective LLMs that can be run on a moderately powerful GPU – allowing you to experiment with these models quickly and efficiently. These LLMs are not just for fun - they're powerful tools for research, text analysis, grammar correction, and even can work as a personal assistant of a kind.
We will work in these steps:
- Download and installation of software to run the chatbot
- Download a fast LLM model
- Starting server with the LLM model running
- Connecting chatbot to the server
Step 1: Installations the Easy Way
We will use 'LMStudio' to easily install models and run the server, and 'AnythingLLM' for chatbot UI and work with documents.
- LMStudio https://lmstudio.ai/
- AnythingLLM chatbot https://useanything.com/
Install both programs and run LMStudio.
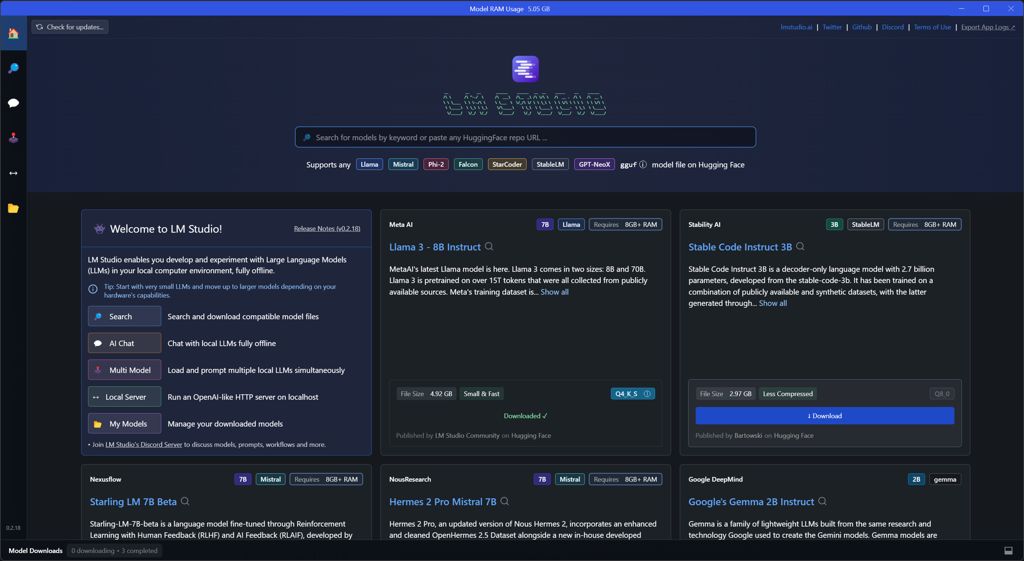
Step 2: Downloading Models and Setup
For LLaMA-3, you may need a Hugging Face account and access to the LLaMA repository. Even then, you can download it from LMStudio – no need to search for the files manually. You can also download many other models directly and conveniently from the LMStudio opening window:
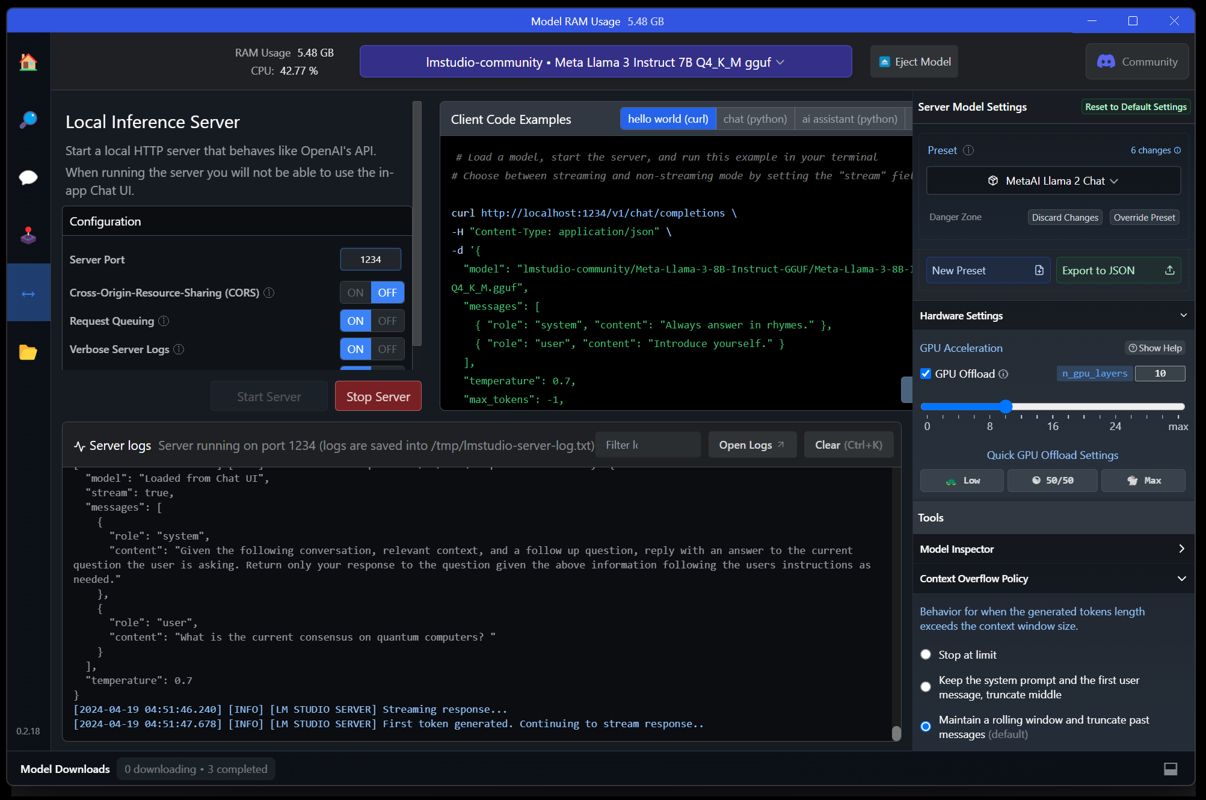
Step 3: Loading Model to the Memory and Starting a Server
- Select 'Llama3' model you downloaded (load it)
- Set 'Llama3' Preset config in the menu on the right (if you are not seeing it there, update your LMStudio to the newest version). After saving settings and reloading the model, you should be able to chat in 'AI Chat window'. You may test it, but we will proceed further.
- Go to 'Local Server' icon in the left menu
- use 'Start Server' button
NOTE: If you change configurations in LMStudio, you need to reload the model and/or server.
Step 4: Connecting AnythingLLM to LMStudio Server
With the LMStudio Server running, start AnythingLLM.
- Go to 'Open settings' (wrench icon)
- Go to 'Instance settings' (cogwheel icon), in LLM Preference set LMStudio as LLM Provider ( this will set LMStudio as the source of model streaming). You may have an option to set these in a wizard when you run the program for the first time. Set Max Tokens your model allows (default 4096)
- In Transcription Model set AnythingLLM and save
- In Embedding Model set AnythingLLM and save
- In Vector Database set LanceDB and save. If you get a database error when trying to chat, set it again and save.
You should now be able to start a new workspace in the left menu and start chatting. Well done, now you are running LLM locally!
Optimizing
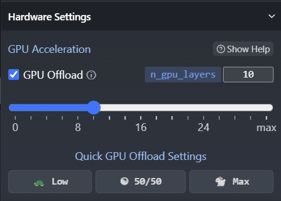
Set the 'GPU offload' setting as high as your GPU allows. Try it in steps at first and check your system monitor on VRAM usage.
Text Embeddings
You can download and switch text embeddings models too. Read more about this in References links.
Llama3
Llama3 is an efficient pre-trained instruction-fine-tuned language model with 8B and 70B parameters, making it suitable for chatting, coding, and document analysis. We’ll be using the 8B version (but the choice is dependent on your resources). Llama3 was developed by Meta and is freely available, boasting good performance even on local machines. I can confirm it’s very fast, and I recommend it if your card can manage a Stable Diffusion SDXL; in that case, Llama3 will run very smoothly.
Mistral/Mixtral and Gemma
The setup of any model is in fact similar—use the correct Preset, download the model and run it on server.
Gemma is a family of lightweight open models from Google, a light version of Gemini kind of. 'Gemma 2B Instruct' has 2,67GB and is very fast.
Mistral is a popular family of many LLM models that you may choose from. Mistral Small is very lightweight and fast, but you can also test any of the ones that your GPU will be able to manage.
There are many other lightweight models that you can try. I recommend testing Phi-2 (Microsoft), Qwen, Stable LM Zephyr 3B. There are also models dedicated specifically to coding.
Connecting LM Studio Server to A1111/Forge
There is a separate article tutorial on how to send prompts from A1111/Forge UI.
Conclusion
By following this practical guide, you've taken the first step towards running LLMs on your own machine (and everything should work as expected). Remember, the possibilities are vast! Experiment with different models, explore their capabilities, and unleash your creativity. As local LLM technology continues to evolve, stay tuned for further updates and explore the ever-expanding world of AI at your fingertips. Happy experimenting!
References
- Llama3 Anouncement Article https://ai.meta.com/blog/meta-llama-3/
- Mistral Model page, https://docs.mistral.ai/ Article https://huggingface.co/docs/transformers/main/en/model_doc/mistral
- Gemma (a smaller version of Google Gemini Model) https://huggingface.co/blog/gemma
- Text Embeddings in LMStudio https://lmstudio.ai/docs/text-embeddings
- AnythingLLM https://github.com/Mintplex-Labs/anything-llm

