Semantic Guidance SDXL: Instructing Diffusion using Semantic Dimensions

When engineering a prompt for stable diffusion, even small changes to the input prompt often result in wildly different output images. This is especially true when using tokens (keywords) with high weight—typically a color, style, or environment. This may lead to some heavy prompt adjustments and in the end to many tiresome experiments. The composition is also at stake unless we are not taking some heavy ControlNet measures.
Luckily now we can use Semantic Guidance to interact with the diffusion process using a comfortable A1111 extension.

What It Does
It uses simple textual descriptions for semantic guidance inferences (SEGA) without any additional segmentation masks. This enables simultaneous edits to images, mitigates some biases of a trained model, and can create slight changes in composition and style, as well as the artistic conception. This is actually very interesting research touching subject of disentanglement models’ latent space and architecture-agnostic quantifications, for the details see the paper in References at the end of this article.
Installation of A1111 Extension
In A1111 web UI go to Extensions/Avalable/Load from. In the list, find Semantic Guidance (sd-webui-semantic-guidance), Install and restart A1111.
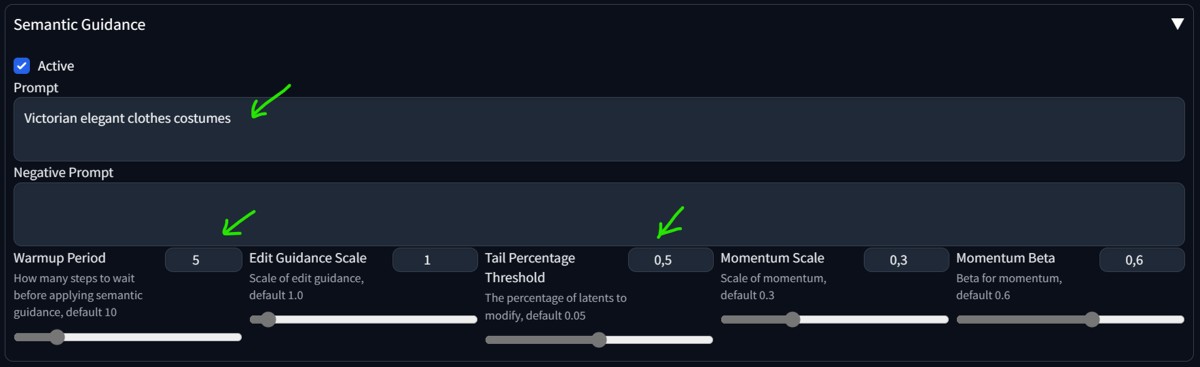
How to Use It
Basic setting is on the image above. Warmup controls at which step Semantic Guidance will start to take effect. Prompt of Semantic Guidance will steer the main prompt you have. In the example, the main prompt "couple mature, fashion clothes, character photo portrait" was adjusted with "Victorian elegant clothes costumes".



For the most common use, adjust warmup steps and set Tail percentage threshold around 0.5. If you want to get closer to your prompt, lower the Edit Guidance Scale option. Momentum Scale and Beta does not seem to have any effect (tested in SDXL).
Implanting LoRA with Semantic Guidance
You may also modify a composition with LoRA model, implanted via Semantic Guidance extension. It brings the benefit of keeping the composition. This is an interesting way of how to use various LoRA styles and translate some features.
LoRAs entered in Semantic Guidance prompts have no effect (yet). You may circumvent this by using keyword tokens (activating words) for a LoRA model in the Semantic Guidance prompt. This is an interesting alternative for LoRA weights in the main prompt (you can combine the effect too). Reminder: LoRA needs to be inserted into the main prompt.

Comparison
It reacts very well in SDXL and it also works in SD 1.5 models. Achieving similar results with different means would be very time and resource consuming. But with combination with Regional Prompter or Latent Couple it could be even more powerful in the future (for now you can not target a single region).
Conclusion
Simplicity. This is the key for using this interesting technique. The extension also does not seem to get in the way of other A1111 addons. This extension is very robust addition to your SD toolbox.
References
- Research https://github.com/ml-research/semantic-image-editing
- A1111 extension https://github.com/v0xie/sd-webui-semantic-guidance
- Paper SEGA: Instructing Text-to-Image Models using Semantic Guidance https://arxiv.org/abs/2301.12247

