Stable Audio Open: Custom Soundscapes and Sound Design Locally

'Stable Audio Open' is a Stable Diffusion model specializing in audio samples, sound effects, and short music elements. It's important to note that Stable Audio Open 1.0 is not designed for full-scale music creation, although it can effectively generate shorter sound clips in various styles, such as rhythmic or drum loops. While it may not surpass the best models currently available, with proper setup and configuration, Stable Audio Open can deliver impressive results.
Installation for ComfyUI
For installation you will need both files, the model itself and t5 text encoder (for ComfyUI Instalaltion and tips read this article):
- Download https://huggingface.co/google-t5/t5-base/blob/main/model.safetensors into folder /models/clip/ and RENAME it to
t5_base.safetensors - You will need to agree to the license for this download. Download https://huggingface.co/stabilityai/stable-audio-open-1.0/blob/main/model.safetensors into ComfyUI /models/checkpoints/ folder (or into models/Stable-diffusion/ if you are linking your model paths to A1111) and RENAME it to
stable_audio_open_1.0.safetensors. - Now you can find a stable audio workflow for comfyUI or use the simplest STABLEAUDIO-workflow.json from my github repo.
Use and Prompting
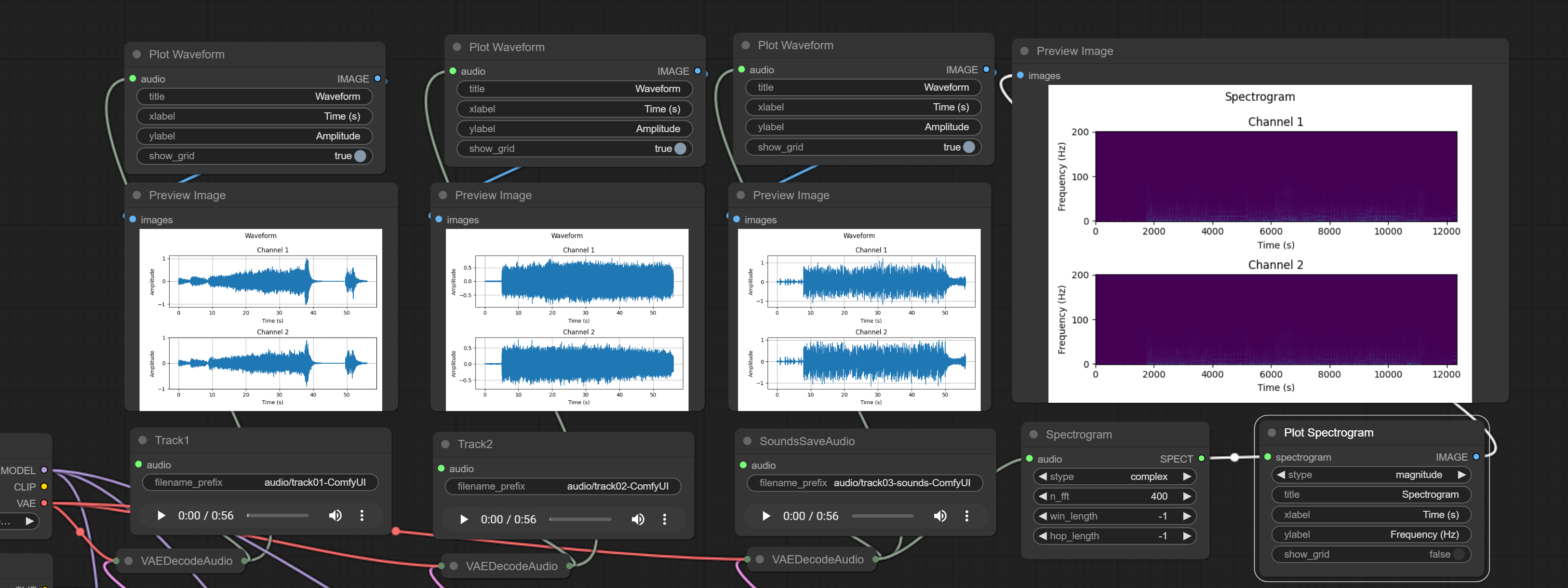
The control is the same like when you generate Stable Diffusion images. Expreriment with various styles of prompting. Stability.ai recommends a structured prompt (For Stability Audio 2.0), however mileage may vary.
Stable Audio Open Test: Sound Design and Soundscapes
Tips
- Use preview for waveforms, see examples. Use Manager for the comfyui-audio-processing nodes.
- Experiment with sampler/scheduler combinations.
- Adjust token weight in similar manner as in SD image generation
- Adjust CFG/steps/seed to get the best results
- If you can not get the result from a single prompt, mix afterwards
- SAO generates shorter (up to 47s) stereo audio at 44.1kHz, however you may test even longer clips (after a 60-80s the result seem to be less precise, around 120s the output becomes bland as it stretches its theme somehow).
Conclusion
While other models may excel in music generation, Stable Audio Open 1.0 stands out for its open-ended possibilities for experimentation. Future versions may offer improved adherence to prompts, but it's important to acknowledge the inherent features and limitations of diffusion models and embrace the aleatoric randomness that is part of their nature. The key lies not in using the models out of the box, but in building upon the technology and customizing it to your specific needs, incorporating your own creations and sounds from field recordings or sound design experiments.
Resources
- Stable Audio Open Paper > https://arxiv.org/html/2407.14358v1#S1
- Stable Audio Open License https://huggingface.co/stabilityai/stable-audio-open-1.0/blob/main/LICENSE.md
- Stable Audio Tools https://github.com/Stability-AI/stable-audio-tools
- Friendly Stable Audio Tools https://github.com/yukara-ikemiya/friendly-stable-audio-tools
- My Stable Audio ComfyUI workflow examples https://github.com/sandner-art/ai-research/tree/main/_STABLEAUDIO

